I. On This Website
I (Dr. Eric T. Karlstrom) am an Emeritus Professor of Geography who taught at the university level for some 30 years. During this time, I taught numerous courses on the topics of climatology, paleoclimatology, landforms, soils, environmental geology, Quaternary environments, and human ecology, etc. and also conducted research in these fields (bio). This website is essentially a “digital library” of information which I make available to the public. The information herein proves that the catastrophic, human-caused global warming scare is a scientific fraud and that this fraud helps to advance various political, economic, corporate, and military/intelligence objectives. The site also identifies these larger, largely unknown and poorly understood objectives.
Perhaps as introduction, the three most important articles/ppt presentations on this site that readers should examine are the following:
1) Open letter to Policy Makers, Colleagues, Students, and Citizens. Disproofs of the Hypothesis of AGW (Anthropogenic Global Warming) (Open Letter PDF).
3) Man-Made Climate Change in the Skies: Or Playing God with the Atmosphere and Earth (ppt).
This website includes seminal scientific papers by U.S. Geological Survey paleoclimatologist, Dr. Thor N.V. Karlstrom in the Frequency of Natural Climate Change section. Dr. T.N.V. Karlstrom dedicated his career to documenting and dating the natural climate cycles that are reflected in the geologic record of the Quaternary Period (last 2 to 3 million years). His “astro-climatic theory”/”solar insolation-tidal resonance model,” is the result of his 60+ years of research. A brief overview of T. Karlstrom’s ideas can be gained by viewing an informal presentation on Natural Climatic Cycles that he made at the University of Massachusetts in 2007 as well as by reading my summary notes of this lecture (Notes on Natural Climatic Cycles; June 5, 2007).
In addition, some of my own most important scientific papers are featured in the Magnitude of Natural Climate Change section. My research on paleosols (ancient soils) and periglacial features permits estimation of the magnitude of past natural climate changes during the Quaternary Period. Discussion of the magnitude and timing of natural climate changes has been absent in the “global warming”/“climate change” debate.
This website also features:
1) numerous articles that I and others have written on these and related topics,
2) numerous power point presentations by climate experts (many of which were presented at the International Conference on Climate Change; 2008 and 2009) and undergraduate students,
3) many audio interviews I have conducted with climate experts, and
4) podcast interviews with noted climate experts.
II. Temperatures Over Time As Shown in Time-Series Diagrams
The following seven time-series graphs show reconstructed temperatures (Y axis) as inferred from various kinds of proxy climate records (Figures 1 – 6) or as measured directly from modern satellites (Figure 7). Time scales (X axis) vary from 600 million years in Figure 1 to 30 years in Figure 7.
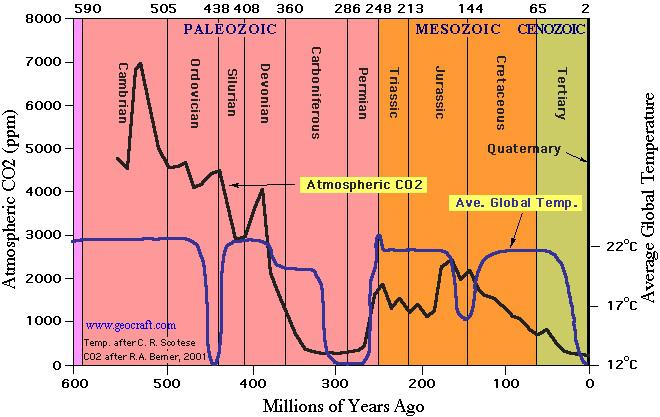
Figure 1
Figure 1 – Average temperature and atmospheric carbon dioxide content over the past 600 million years (after Scotese and Bernier, 2001 from GEOCARB III project). Note there is no correlation between average temperatures (blue line) and atmospheric CO2 concentrations (gray line). Also note that average temperatures and atmospheric CO2 concentrations today (lower right side of figure) are much lower than for most of the past 600 million years.
Figure 2 – Progressive cooling trend over the past 65 million years based on oxygen-isotope ratios in fossilized floating animal shells. The present is to the left in this figure.
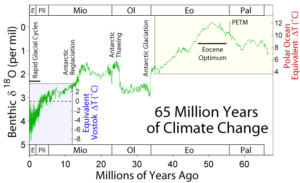
Figure 2
Figure 3 – Temperature fluctuations over the past 5.5 million years based on oxygen-isotope ratios in sediment cores. (The present is to the right). Note: 1) general cooling trend over the last 3 million years, 2) large temperature swings beginning 2.67 million years ago corresponding to the present ice age, 3) present climate is cooler than during the earlier Pliocene and Miocene Epochs (5.5 to 2.5 Ma), and 4) magnitude of temperature fluctuations increases towards the present. Note the apparent importance of the 41,000-year obliquity cycle in the earlier part of the present ice age and the 100,000-year eccentricity cycle during the last one million years. These cycles are attributed to periodic variations in the earth’s orbit around the sun (as per the Milankovitch, or astronomic, theory of climate change).
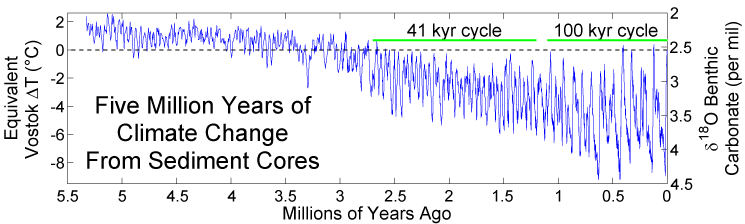
Figure 3
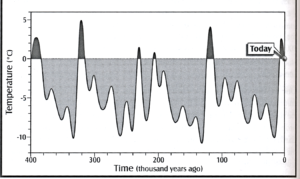
Figure 4
Figure 4 – A composite figure from hundreds of deep-sea cores that shows temperature fluctuations associated with glacial (grey) and interglacials (black) climate cycles over the last 400,000 years. Note that: 1) the current interglacial (black blip on far right) is cooler than previous interglacials, 2) the cyclical/periodic nature of temperature fluctuations suggest the present interglacial will soon be followed by another glaciation, and 3) there is nothing extraordinary about present temperatures.
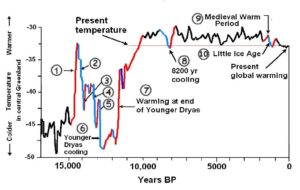
Figure 5
Figure 5 – Magnitude and timing of temperature fluctuations over the past 17,000 years as recorded in the oxygen-isotope record from Greenland and Antarctic ice cores. These data show numerous abrupt climate changes with magnitudes many times greater than those of the past century. Numbers and red and blue colors correspond to intervals of rapid warming and cooling. Note that the general trend over the past 5000 years is toward progressive cooling toward the present (right).
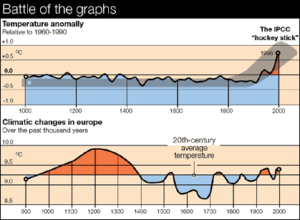
Figure 6
Figure 6 – Note Mann et. al.’s “hockey stick” (upper diagram) of estimated temperatures based on tree-ring studies does not record the Medieval Warm Period (900-1300 AD) or the Little Ice Age (1300-1850 AD) that are typical in most proxy paleoclimatic records. Rather, Mann et al.’s upper figure shows an abrupt 20th Century warming following about 1000 years of climatic stability. By contrast, the temperature history of the past 1000 years derived from hundreds of other studies indicates that the Medieval Warming and the intense cold of the Little Ice Age were the most extreme events of the past 1000 years (lower diagram). The Mann et. al. “hockey stick,” contradicted by hundreds of validated previous studies, was a centerpiece of the IPCC’s Third Assessment Report in 2001 and was featured in Al Gore’s movie, “An Inconvenient Truth.”
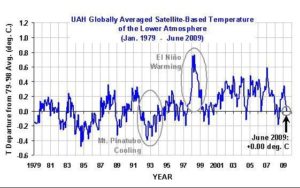
Figure 7
Figure 7 – Globally averaged satellite-based temperature of lower troposphere from 1979 to 2009, from University of Alabama-Huntsville Climate Center. Note slight cooling trend between peak temperatures of 1998 and 2009.
III. Human-Caused Global Warming Fraud
Many, many top, international scientists have concluded that the hypothesis of AGW (Anthropogenic Global Warming) is resoundingly disproven by the scientific evidence (AGW Quotes, Quotes on IPCC Fraud). In addition, since in contradiction of all the climate models, the earth’s temperature has actually cooled slightly since 1998, reality itself disproves this hypothesis.
Therefore, we, the informed and skeptical public, must ask why our leaders want to spend trillions of our tax dollars to “fix” the climate… and a problem that does not exist. Meteorologist Mark Nolan stated:
I’m not sure which is more arrogant – to say we caused [global warming] or that we can fix it.
Part of the propaganda is that we are told that a “consensus” of scientists “believe” in human-induced global warming. Not true. Stating the sentiments of the majority of scientists, Ohio meteorologist Dan Webster observed:
In my dealings with meteorologists nationwide, ‘about 95% share my skepticism about global warming.‘
Indeed, many top scientists ridicule the idea as foolishness. Dr. Reid Bryson, who has been called the “father of modern scientific climatology,” stated:
You can go outside and spit and have the same effect as doubling carbon dioxide. All this argument is the temperature going up or not, it’s absurd. Of course it’s going up. It has gone up since the early 1800’s, before the Industrial Revolution, because we’re coming out of the Little Ice Age, not because we’re putting more carbon dioxide into the air.
Of course, before any group of scientists or policy makers can hope to evaluate whether or not human activities are causing disastrous “global warming”/aka “climate change”/aka “climate disruption,” they first need to gain a basic understanding of the magnitude and timing of the natural climate changes that have occurred over time. Amazingly however, the United Nations’ IPCC (Intergovernmental Panel on Climate Change) completely ignores the effects of natural climate fluctuations! Indeed, the U.N.’s IPCC working definition of “climate change” mostly excludes natural climate change!
Climate Change: “A Change of climate which is attributed directly or indirectly to human activity that alters the composition of the global atmosphere and which is in addition to natural climate variability observed over comparable time periods.”
– IPPC definition (under United Nations Framework Convention on Climate Change or FCCC)
Hence, Dr. Roy Spencer, in testimony before US Senate Environment and Public Works Committee, and MIT meteorologist, Dr. Richard Lindzen (respectively) state:
Given that virtually no research into possible natural explanations for global warming has been performed, it is time for scientific objectivity and integrity to be restored to the field of global warming research.
The consensus was reached before the research had even begun.
Certainly, earth scientists understand very well that the earth’s climate:
1) has changed radically during it’s 4.6 billion year history,
2) has been much warmer than present for about 80% of the earth’s history (see above figure), and
3) that living things tend to do much better during warmer climates than colder climates!
Indeed, earth scientists have amassed an impressive body of research in the field of paleoclimatology, or climates of the past. However, there is still no generally accepted theory of climate change. Perhaps this explains why U.N. bureaucrats and ideologues have gotten away with making radically simplifying (and erroneous) assumptions about the climate system in their computer models.
Because of the potentially disastrous consequences of adopting some of the solutions that have been proposed to solve the alleged problem of “climate change,” including imposition of carbon taxes, “cap and trade” schemes, carbon sequestration, geo-engineering, etc., I herein summarize some of the more important aspects of what is known about natural climate change. Before our society is stampeded into political solutions to an alleged problem that many scientists, including myself, realize does not exist, it is essential that our citizenry and our politicians try to learn from genuine climate experts whose voices are often not heard. Among these voices are some of the most distinguished climate and paleoclimate researchers featured in the articles, power points, audio interviews, and podcasts on this website).
I also feature on this website many quotes on the topic of man-caused global warming by various experts (Quotes On Global Warming). These statements were compiled by the U.S. Senate Minority Report entitled: “More Than 700 International Scientists Dissent Over Man-Made Global Warming Claims.” In addition, I list many useful books, articles, DVDs, and government reports on the controversial topic of the “Global Warming Hoax” (References on Global Warming Hoax).
Perhaps the best defense against the “man-caused global warming” propaganda offense, then, is: 1) clear articulation of the scientific facts, and 2) an expose of the propaganda system and explanation of what this “system” hopes to accomplish. It is actually quite easy for legitimate earth/climate scientists to disprove the bogus hypothesis of man-caused global warming (see my “Open Letter: Disproofs of Man-Induced Global Warming” paper). But normal scientific protocols are not operative in this case…. for this is no ordinary scientific hypothesis. Rather, this contrived bit of pseudo-science forms a lynch pin in a United Nations (prototype world government) plan to seize control of world resources and economic activity through U.N. Agenda 21 (Agenda for the 21st Century) and other policy initiatives.
IV. Some Basic Earth Science
In the following statements, I summarize the pertinent headlines from the real (as opposed to the virtual- or computer-generated) science of climatology/paleoclimatology/earth science:
- Earth scientists have learned that earth was significantly warmer than present (by perhaps about 8 to 10 °C) for about 80% of the earth’s 4.6-billion-year history (see temperature and CO2 reconstructions for past 600 million years in figure above).
- From a historical as well as a geological perspective, warming trends are beneficial for humans, for agriculture, and for plants and animals. No “tipping points’ were reached during past geologic intervals when temperatures and CO2 concentrations were much higher than present. In fact, life flourished during these relatively warmer conditions.
- For the past 2 million years (Quaternary Period), the earth has been in an ice age comprised of some 20 major glacial/interglacial cycles. Each cycle was characterized by very wide swings of temperature and precipitation.
- For the past 10,000 years, the earth has experienced an unusually warm and stable (interglacial) climate known as the Holocene Epoch. The stable and favorable climate of this interglacial allowed for the development of agriculture and human civilization.
- 71% of the earth is covered with ocean water. 90% of the world’s ice is in Antarctica. Our instrumental climate records only extend about 100 to 150 years back. There are still not enough weather stations on the earth to determine the average temperature of the earth. The best data from satellites and the Argo (ocean robot) systems suggests the planet has been cooling slightly since 1998.
- Exhaustive analyses of proxy paleoclimatic records (deep sea cores, ice cores, tree-rings, glacial deposits, soils, loess sequences, cave deposits, pollen studies, etc.) by scientists reveal that past climate changes are complex and of varying frequency and magnitude. There is still much we still don’t agree on. Many scientists, including myself, believe climate change is cyclical and these cycles are of varying periodicities.
- The main climate drivers include variations in solar output, ocean circulation dynamics (the ocean stores some 22 times more heat than the atmosphere and circulates that heat around the globe), and orbital variations in the earth-sun-moon system.
- Carbon dioxide has a negligible effect on atmospheric temperatures. Rather, because the oceans hold about 50 times more CO2 than the atmosphere, and because the oceans and atmosphere exchange CO2, CO2 fluctuations are mainly caused by changes in ocean temperatures. And ocean temperature changes are mainly driven by the sun.
- Because we have seasons, the earth is constantly warming and cooling in various locales. Weather and climate change is a constant. But is the earth as a whole warming or cooling? The answer to this question depends entirely upon the length of the climate record being analyzed. On the basis of many paleoclimatic records, earth scientists agree that the general trend over the past 3 million years has been toward cooling; the trend over the past 15,000 years has been toward warming; the trend over the past 5,000 years has been toward cooling; and there has been a warming trend since Little Ice Age maxima about 1650 AD. The earth warmed very slightly between about 1975 and 1998, and since 1998 the trend has been toward cooling.
Regarding the many ancillary “alarmist” claims (propaganda ploys) that the media reports almost daily, these too are lies. As I point out in my “Disproofs of Man-Caused Global Warming” paper (this website):
1) CO2 is not harmful at all. Conversely, this trace gas (comprising about 4 molecules in 10,000) is essential for photosynthesis and hence, for all life on the planet!
2) As noted, the claim that atmospheric CO2 concentrations have been rising in the atmosphere is based on “cooked” data. In reality, there has been very little to no increase in either CO2 or temperature over the past 100 years. We are simply looking here at science fraud, which apparently pays well enough to motivate some scientists to commit that fraud.
3) The earth has been cooling very slightly since 1998. Thus, all the computer projections of future warming are proven to be wrong.
4) Sea levels have been rising by a modest 7 inches/century for the past 350 years or so, as the earth has been warming from the coldest part of the Little Ice Age. There has been no increase in rates of sea level rise due to human industrial activity over the past 150 years. Current best estimates are that world sea levels are now rising by less than the thickness of a nickel each year (about 1.5 mm). However, sea level changes are very complex and this is just an average figure.
5) Polar bear populations have expanded in the northern hemisphere during the past 50 years. Like most other organisms, polar bears do better in warmer climates. Incidentally, they can swim 100 miles or more, if they need to.
6) There has not been an increase in the number of extreme weather events in the latter part of the 20th century. However, extreme events of recent decades could be due to human activity…. namely, geoengineering/weather warfare/weather modification (see section with that title).
7) The net amount of glacier ice on the planet may have actually increased during the last 100 years or so. Nearly 95% of the world’s ice is located in its two ice caps; Antarctica, which has been cooling for the past 40 years, and Greenland, which seems to have warmed slightly but whose interior ice sheet has thickened. Whereas some mid-latitude mountain glaciers are retreating, an equal number is advancing. In any event, mid-latitude glaciers hold a small percentage of the world’s ice (about 5%).
8) Tropical diseases are not spreading due to human industrial activity.
9) There has been no mass extinction of species in the past 100 years.
V. Behind the Anthropogenic Global Warming Fraud
Why, then, are we repeatedly told just the opposite of the truth, as summarized above? Alas, the young science of climatology has now been thoroughly “politicized,” that is, to say, it has been co-opted and corrupted by political and economic agendas. (Other instances of sciences that have been co-opted and corrupted to serve political objectives include the phony “sciences” of eugenics and “Lysenkoism,” to name just two historic examples.) Thus, in the climate change issue, we are no longer dealing with science, per se, but rather with political propaganda. Thus, while much of this site is dedicated to addressing the real science, it is also imperative to try to understand the political/economic objectives associated with the man-caused global warming fraud. These goals can summed up as control of resources and human populations, world government, de-industrialization of industrial countries, and depopulation.
I recently gained an unexpected insight when viewing a 1985 BBC TV series entitled “The Day the Universe Changed.” It was a fast-paced waltz through the history of scientific discovery and invention, narrated by science historian, James Burke. The last program focused on two seemingly unrelated subjects: supercomputers and Tibetan Buddhism, with the camera flipping back and forth between banks of Cray supercomputers and chanting Tibetan Buddhists. Burke ended the series with the remark: “In the age of supercomputers, reality is what we say it is.”
Well, that helps explain the emphasis on supercomputers. But what is the point of including the Buddhists? Perhaps the message is that “reality is in the mind” as well as “perceptions can be managed and manipulated.” The global warming hoax, I’m afraid, is a perfect example of what happens when virtual (or computer- and propaganda-generated) reality is intentionally confused with real reality, which, in this case, is the actual physical world we live in.
However, before we all disengage our critical thought processes and don Buddhist robes, perhaps we should consider these (for me, hard-won) insights:
1) The BBC is the propaganda arm of the British government……
2) The British government more or less controls the United Nations…. (Hear audio interview with Joan Veon under Global Government section.)
3) The United Nations created the IPCC (Inter-governmental Panel on Climate Change), Agenda 21 (Agenda for the 21st century), Kyoto Protocol carbon trading solutions, and is intended to be the prototypical world government…..
4) According to former British intelligence officer and political scientist, Dr. John Coleman, the Tavistock Institute on Human Relations in London, England grew out of the Psychological Warfare Division of the British Army in World War I and remains the world’s brainwashing center. Coleman notes that Tavistock and its many spinoff organizations in America and elsewhere have been waging psychological warfare on the American people for many decades.
With the help of these insights, perhaps we can now begin to understand what is really happening here. Certainly, the science of climatology has been hi-jacked to fulfill a political agenda that is incessantly advanced by media propaganda. But beyond that, it would seem that the man-caused global warming fraud is also a form of fear-mongering and brainwashing. Shamefully, this fraud is used to frighten young children into believing that humans are destroying the earth and that they have no future.
Certainly, “global warming” forms the centerpiece of a much larger United Nations plan to control the world’s resources, physical environment, and all human activities, as envisioned in U.N. Agenda 21! This explains why the global warming fraud is reinforced by incessant repetition of lies and propaganda by politicians, academics, the media, (particularly the BBC), environmentalists, and even grant-hungry scientists who “go along to get along.” This also explains why adequate understanding of this issue/problem requires much more than just proving or disproving a particularly weak scientific hypothesis.
Indeed, this particular hoax or swindle seems to involve the systematic application of very sophisticated (fear- and trauma-based) mind control techniques characterized by the deliberate obfuscation of reality and virtual reality. As Burke stated: “In the age of computers, reality is what we say it is.” Or as British intelligence officer and author of 1984, George Orwell stated: “If both the past and the external world exist only in the mind, and if the mind itself is controllable- what then?” Orwell answered his own question as follows: “Who controls the past controls the future; who controls the present controls the past.”
Indeed, this dynamic is quite clearly manifest in the systematic falsifications of weather and climate data carried out by national weather services in Britain, America, New Zealand, and Australia! The names of the recent (2009) climate science scandals are familiar to many: “Climate-gate,” “NASA-gate,” “Kiwi-gate,” and “Aussie-gate.”
In all these cases, national weather services fudged data to make it appear that there has been a 1 degree F. warming in the 20th century. Of New Zealand’s NIWA (National Institute of Water and Atmospheric Research) data manipulations, James Delingpole noted:
The shocking truth is that the oldest readings have been cranked way down and later readings artificially lifted to give a false impression of warming. One station, Hokitika, had its early temperatures reduced by a huge 1.3° C, creating a strong warming from a mild cooling. We have discovered warming in New Zealand over the past 156 years was indeed man-made, but it had nothing to do with emissions of CO2- it was created by man-adjustments of the temperature. It’s a disgrace.
Then there is the fraudulent and now disproven “Hockey Stick graph” of Mann et al., 1998 (used in Al Gore’s movie, etc.) which “disappeared” the natural climate changes (Medieval Warm Period and Little Ice Age) in temperature records of the past 1000 years so as to exaggerate the “modern warming” of the second half of the 20th century. (Thus, the graph appears like a hockey stick with it’s blade pointing upward toward the present day). To demonstrate that warming of the earth during the past century is due to human industrial activity, various “pseudo-scientists” have also misrepresented CO2 trends as well. In fact, this is another case of selection of data to justify the propaganda.
To combat the fierce global warming propaganda, then, I offer the following conclusions derived from the evidence provided in articles, power point presentations, and audio interviews on this site:
- The idea that human’s are causing disastrous climate change by burning fossil fuels is pseudo-science, mass brainwashing, and social engineering that serves various political/economic agendas.
- This pseudo-science fraud is being “justified” mainly by output from computer models, which essentially are black-box simulations of the climate system. Assumptions and parameters incorporated in these computer models are generally programmed to yield the “proper” results, including “projections” or “scenarios” of “global warming” in the next hundred years or so. This is a dramatic example of what is known in computer science as “Garbage In, Garbage Out” or GIGO.
- CO2 is singled out as the single cause of global warming, of course, because it is a by-product of the burning of fossil fuels, which provides about 85% of all energy consumption worldwide.
- There is a direct one to one correlation between energy use and wealth. Hence, reducing use of fossil fuel energy by 80%, as called for in Phase II of the Kyoto Protocol, would result in an 80% reduction of wealth. It would also result in significant de-industrialization and depopulation, which are also elite goals articulated in United Nations documents:
A reasonable (population) estimate for an industrialized world society at the present North American material standard of living would be 1 billion. At a more frugal European standard of living, 2 to 3 billion would be possible.
United Nations, Global Biodiversity Assessment
- Wind and solar power are, by their very nature intermittent and diffuse sources of energy. They are the “perpetual 10 to 20% solution.” Hence, wind and solar power will never substitute for fossil fuel energy.
- Media, politicians, think tanks, public relations agencies, environmental non-profits, schools, universities, and even scientific research institutes and national weather services have all been enlisted to “sell” this “big lie” to the public. It is now a multi-trillion dollar industry.
- Most of the individuals involved in promoting this agenda are well-intentioned but are ignorant of the patterns of climate change that have occurred naturally during the earth’s very long and complex history. Typically, they are driven by their “green” ideology/religion and/or their self-interest and/or their hatred of humans.
- The idea of “using” environmental degradation, including man-caused global warming, as a “common enemy to unite us all” emerged from think tanks that are spin-offs of the Tavistock Institute of Human Relations, the world’s brainwashing center in England. The strategy was articulated in documents produced by the Rand Corporation (The Report from Iron Mountain, 1967) and the Club of Rome (The First Global Revolution: A Report by the Council of the Club of Rome,1973), in particular. The First Global Revolution states:
In searching for a new enemy to unite us, we came up with the idea that pollution, the threat of global warming, water shortages, famine and the like would fit the bill.
Another Tavistock Institute spinoff, the Institute for Public Policy Research (also in London), recently outlined the public relations strategies to be used by politicians and others to “sell” global warming to the public in a 2006 report:
The task of climate change agencies is not to persuade by rational argument….. Instead, we need to work in a more shrewd and contemporary way, using subtle techniques of engagement…. The ‘facts’ need to be treated as being so taken-for-granted that they need not be spoken.
Unfortunately, positive climate behaviours need to be approached in the same way as marketers approach acts of buying and consuming…. It amounts to treating climate friendly activity as a brand that can be sold. This, we believe, is the route to mass behaviour change.
Just what “mass behaviour changes” are desired by the authors of the above statement? This becomes clear when one learns a little about the United Nations’ Agenda 21 (Agenda for the 21st century), a 300-page soft law document which has been adopted by nearly all the nations of the world (just as nearly all the nations of the world have signed on as participants with the IPCC).
Today, many government and United Nations documents utilize the hyped, fabricated threat of man-caused global warming as justification for several major policy “solutions.” Rosa Koire (Behind the Green Mask: U.N. Agenda 21) reveals the intended goals:
This plan is a whole life plan. It involves the educational system, the energy market, the transportation system, the governmental system, the health care system, food production, and more. It is a plan to inventory and control all of the natural resources, means of production, and human beings in the world. The plan is to restrict your choices, limit your funds, narrow your freedoms, and take away your voice.
Agenda 21 has much in common with Karl Marx’s communist (now called “communitarian”) utopian vision. For Americans, its implementation would mean the loss of individual rights, the U.S. Constitution, national sovereignty, property rights, and much of their personal freedom, mobility, and wealth. (But the elite, of course, would fair well!). The following map, now commonly referred to as the “Agenda 21 Map of Death,” unveiled at the time of the U.N. Rio Earth Summit (1992), would make about 50% of America off limits to American citizens!:
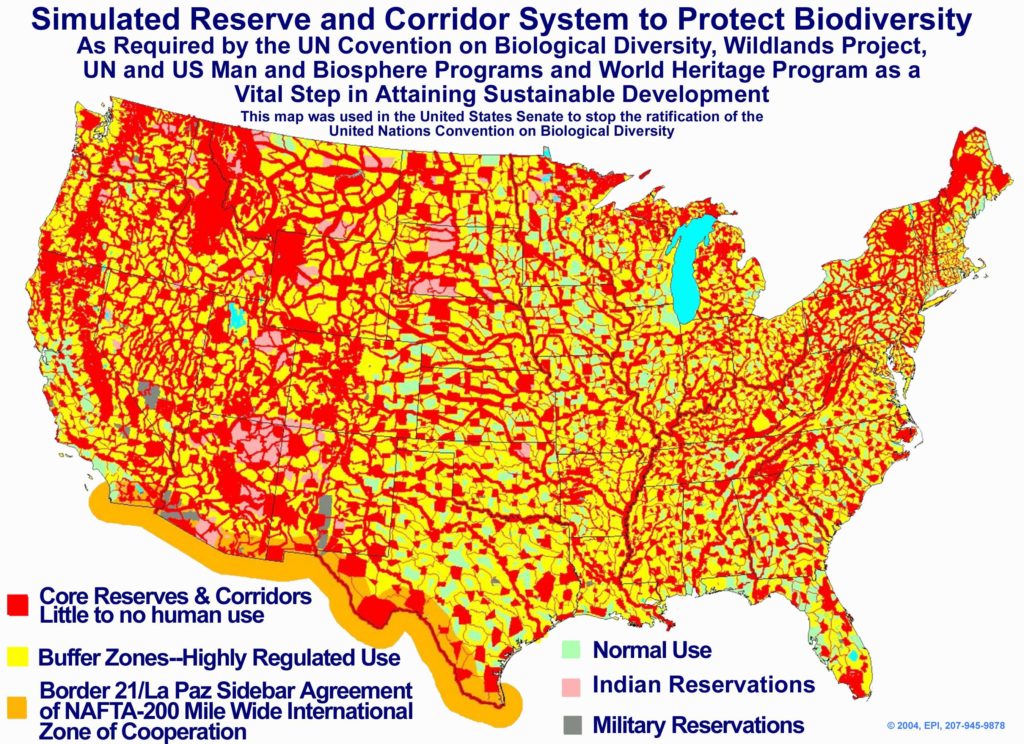
Figure 8 – Simulated Reserve and Corridor System to Protect Biodiversity
In service of U.N. Agenda 21, former British Prime Minister, Gordon Brown, among others, succinctly stated: “Global problems require global solutions.” I.e., “global” warming requires that an international body such as the United Nations control global economic activity and resources.
Other government documents, such as Policy Implications of Greenhouse Warming: Mitigation, Adaptation, and the Science Base (National Academy of Sciences Press, 1992), as well as several recent (2010) U.S. Congressional and U.K. House of Commons bills, call for two main responses to the purported global warming emergency: The “Plan A solution“ requires imposition of “carbon taxes” and “cap and trade” schemes (as per Kyoto Protocol type “solutions”) by which economic activity is increasingly regulated by the United Nations. “Plan B” includes systematic use of “geo-engineering” (including “Solar Radiation Management”) to “mitigate” or “fix the climate.”
In fact, geo-engineering/weather modification/weather warfare is our current reality. Most Americans are unaware that geo-engineering has a 70+-year, mostly secret history, and that geo-engineering is currently being utilized by military agencies and governments, including those of the United States, Britain, China, Russia, and the United Nations, amongst others. There have indeed been fundamental changes to the global atmosphere in recent decades resulting from the significant additions of a whole suite of chemicals and particulates (so-called chemtrails or “persisting contrails”) via aerial spraying as well as additions of vast amounts of electromagnetic energy to the atmosphere from HAARP, GWEN, and other facilities. Indeed, many of the “extreme weather events” of recent decades could well have been geoengineered by our military forces, as a form of covert warfare against domestic populations.
Indeed, in my “Man-Made Climate Change in the Skies” power point presentation, I conclude that the “global warming” story has always functioned as a “cover story” to fund geoengineering/weather warfare projects. (Apparently, if Agenda 21 doesn’t give the “controllers” sufficient control over all systems, human and otherwise, they also have the capability to alter weather and conduct covert warfare against civilians via the technologies of geo-engineering.)
Thus, “global warming” appears to be the cover story and justification for governments to impose two kinds of social control: social engineering and geoengineering. Both of these amount to forms of terrorism, that is, war directed at the civilian population. In her book, Behind the Green Mask: U.N. Agenda 21, Rosa Koire explains the strategy of our (Tavistock Institute-affiliated) social engineers:
Terror in our country is considered external (the 9/11 story), internal (the anthrax story, the “shoe bomber” story), and global (the climate change story)… The story justifies control i.e. the USA Patriot Act, increased domestic surveillance, searches, no-fly lists, and land use, energy use, transportation, and education restrictions and indoctrinations.
In this website, as well as in my www.911nwo.com website, I provide evidence that both the 9/11 and the man-caused global warming terror stories are fabrications. These and other fabricated terror stories are so ludicrous that they insult our intelligence. In effect, they program us to develop the capacity of “double-think.” As defined in George Orwell’s 1984., “double-think” is the act of simultaneously accepting two mutually contradictory beliefs as correct. This appears to be a deliberate attempt to undermine and/or destroy the public’s ability to think rationally and critically. Another term, of course, is “trauma-based mind control.” In fact, researchers such as Jerry Smith conclude that the primary purpose of the HAARP facility is mind control of the domestic populace (see/hear audio interview under Geoengineering heading).
Recall that I previously stated that the Club of Rome and the Rand Corporation are two of the many spinoff organizations of the Tavistock Institute of Human Relations in London, England. In his book, The Tavistock Institute of Human Relations; Shaping the Moral, Spiritual, Cultural, Political, and Economic Decline of the United States of America, former British intelligence officer, Dr. John Coleman, states:
… two important intersecting developments (occurred during WWII): the arrival of émigré psychological warfare expert Kurt Lewin in Iowa, and the involvement of the United States in World War II. World War II provided the emerging Tavistock social sciences scientists with enormous scope for experimentation. Lewin’s leadership put together the key-force that would deploy after World War II to utilize the techniques developed in warfare against the population of the United States. In fact, in 1946, Tavistock declared war on the civilian population of the United States and has remained in a state of war ever since.
Other Tavistock Institute spinoffs, according to Coleman (2006), are the Stanford Research Institute, the Wharton School of Economics, the National Training Laboratories, the National Institute for Mental Health, the National Resources Defense Council, the Committee on National Morale, the Harvard Psychological Clinic, MIT Alfred P. Sloan School of Management, the FBI, and the CIA, amongst many others.
Wake up and smell the coffee, my fellow Americans. Osama bin Laden was never was our enemy. (Indeed, he was a CIA agent for some 20 years and like Lee Harvey Oswald, was simply the designated “patsy” in the 9/11 story.) Likewise, global warming is neither immanent nor is it harmful. Our real enemies consist mainly of the global financial manipulators and their minions who include the social engineers and behavioral scientists of the Tavistock Institute and its myriad spinoff organizations in America and the geoengineers in our military-industrial-complex.
Conclusion: Behind the anthropogenic global warming fraud are the totalitarian designs of an international power elite.
Other Websites Hosted by Dr. Eric T. Karlstrom
http://sanluisvalleywaterwatch.com
http://gangstalkingmindcontrolcults.com
http://erickarlstrom.com



